
He had no idea that the engineer leaving had been running at 127% utilization for the better part of six months. He had no idea that the guy two desks over – the one who “seemed fine” – was quietly interviewing elsewhere too. And he had absolutely no idea that the role he was about to post didn’t actually match the gap his team had. He was hiring for the seat, not for the problem. That’s not a hiring problem. That’s a visibility problem dressed up as a staffing crisis.
How the Problem Gets Built, One Quarter at a Time
“If your hiring decisions are made with one data point: someone is overwhelmed, or someone just left. Neither one tells you what you actually need.”
Staffing problems in MSPs don’t usually arrive as emergencies. They accumulate quietly. An engineer starts handling a little more than their fair share because they’re fast and reliable. Nobody adjusts the ticket routing. The queue grows. The engineer compensates by working faster, then longer, then weekends. Meanwhile, the newer hire who was supposed to be ramping is still at 40% utilization because nobody built a proper onboarding track for them either. By the time the resignation lands, you’ve got three intertwined problems masquerading as one: overload you never measured, attrition you didn’t see coming, and a skills gap nobody ever documented. You post a job req that’s essentially a copy of the last one. You hire for a version of your team that no longer exists. The real failure isn’t the hire itself. It’s that there was no data feeding the decision. Utilization was a gut feel. Skills were assumed. Capacity was invisible.
What This Actually Looks Like Under the Hood
The Version of This Story Found in Forums
Pull up r/msp any given week and you’ll find some variation of the same post. “Lost my best tech, need to replace him fast, what should I pay?” The comments are helpful but they’re sometime solving the wrong problem. They’re talking about comp bands, recruiting pipelines, technical interview questions. Nobody asks: do you actually know what that tech was doing? Do you know which clients he owned? Do you know what percentage of your total billable capacity just walked out the door? The follow-up posts are even more telling. “Hired someone, three months in and things are still terrible.” Of course they are. You didn’t hire into a defined gap. You hired into a panic. The new person is ramping while the remaining team is still maxed out. The queue didn’t get shorter. It got worse while you interviewed. This is a pattern, not a personnel problem. And patterns require systems, not just better recruiting.$40K–$80K
Estimated loaded cost of a bad technical hire at a small MSP, including recruiting, ramp time, and productivity loss
68%
of MSP operators in a 2024 industry survey cited “unclear capacity visibility” as a factor in their most recent staffing mistake
90 days
Minimum ramp time for a new L2 tech at most MSPs – during which the existing team absorbs the ticket load
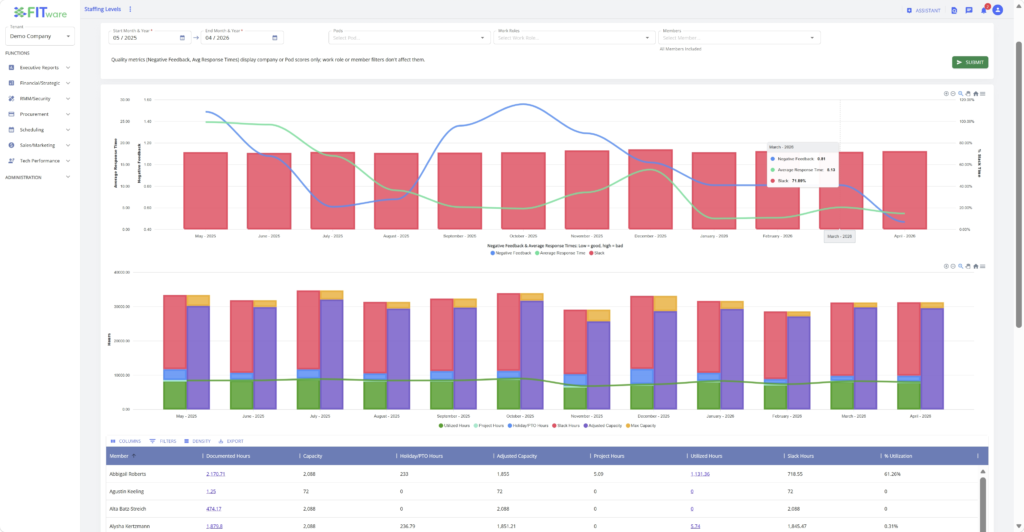
The mechanics are simple when you see them laid out. One engineer is at 127% utilization – meaning they’re regularly working through lunch, taking calls at 6pm, and handling escalations that should have been triaged. They haven’t complained loudly enough to trigger a management response. They’ve just gotten quieter. Another engineer just gave notice. She was at 71% – not overloaded by the numbers, but she’d already mentally left. The third engineer is new, running at 42%, still learning the stack, and will be useless as a capacity buffer for another two months minimum. The fourth position is open. If you post a generic L2 job req and fill it, you haven’t solved anything. The person running at 127% is still running at 127%. When the new hire starts ramping, the existing team has to train them, which adds load to the people who can least afford it. You’ve spent $12,000 on recruiting to not move the needle on the actual problem. The fix isn’t the hire. The fix is the data that tells you what the hire should actually solve.
The Panic Hire
This is the most common and the most forgivable. Someone quits or an SLA breach finally makes it impossible to ignore the queue. You react. You post. You hire. The problem is that the hire is calibrated to the pain, not to the gap. You needed someone who could immediately handle the ticket types that were drowning your senior engineer. Instead you hired whoever interviewed well and seemed like a “fit.” Three months later, senior is still doing the heavy lifting.The Invisible Overload
This one does the most long-term damage. Your best engineer is quietly handling more than anyone knows. They’re good at it, so it looks fine from the outside. Then one day they accept an offer elsewhere and you find out on a Friday afternoon that they were running at 130% for the better part of a year. You’re not just losing a headcount – you’re losing the person who carried half your client relationships and solved the problems nobody else could.The Credential Mismatch
This one stings. A strong resume, a great interview, certifications that looked perfect on paper. But nobody asked what the team’s actual skill gaps were before writing the job req. Your stack is 80% on-premise and aging infrastructure. You hired someone who lives in Azure and cloud architecture. They’re not bad, they’re just answering a question nobody actually asked. Meanwhile, your backup for on-prem Hyper-V just went from one person to nobody.The Hidden Cost of Getting This Wrong
The visible cost is the recruiting fee, the onboarding time, and the salary. The hidden cost is what happens to the rest of your team while the wrong hire ramps. Your good engineers absorb the training overhead. Client satisfaction wobbles because the person who knew those accounts is gone and the new person doesn’t yet. Ticket response times creep up. You start offering credits or service adjustments that come straight out of margin. There’s also the talent retention spiral. When good engineers watch a peer hired for a role that doesn’t match the team’s actual need – and then watch that person struggle while they carry the load – they start updating their LinkedIn profiles. The hiring problem becomes a retention problem. The retention problem becomes a client experience problem. FITware’s Productive Hours report, Staffing Levels report and Tech Skills module exist to reduce this chain of events. When you can see productive hours and utilization per engineer in real time, you don’t have to wait for someone to quit to know they’re drowning. The Tech Skills module surfaces the specific capability gaps on your team – not guesses, but a structured view of what expertise you have and what’s missing – so the job req you write actually solves the problem you have.
What Good Looks Like: A Real Turnaround
What Good Looks Like: A Real Turnaround
A 22-person MSP in the southeast was about to post their third L2 tech role in 18 months. Two previous hires hadn’t worked out. Not bad people but wrong hires. Before posting again, the owner sat down with their Staffing Levels data for the first time and looked at actual utilization numbers across his team. What he found surprised him. He didn’t need an L2. He needed to redistribute load off his one senior L3 who was handling all the escalations for their three largest accounts. The answer wasn’t another hire – it was a promotion and a restructure. He promoted an internal L2 who’d been under-utilized and craving a challenge, reallocated ticket routing, and used the hiring budget on a junior L1 to absorb the lower-tier queue. The results: his senior tech’s utilization dropped. No expensive external hire. No recruiting cycle. And a team morale bump because someone finally got recognized for being ready to grow. The data changed the decision. That’s all it took.
Building a System Around This, Not Gut Instinct
The four-step playbook above isn’t complicated. Pull utilization data before you post anything. Map your actual skills gaps using a structured module, not a whiteboard conversation. Write the job req from the gap, not from the last req you used. And after the hire, track their ramp on the same utilization dashboard so you know whether the gap actually closed. The reason most MSPs don’t do this isn’t laziness. It’s that the data hasn’t historically been easy to surface. Utilization was buried in the PSA, skills were in someone’s head, and there was no single place where you could see both together. When the conversation moves from “we need to hire” to “here’s exactly what we need and why,” the whole organization operates differently. Recruiters give you better candidates. Interviewers know what they’re testing for. Onboarding has a measurable goal. And the people already on your team stop wondering if anyone noticed they were drowning. The MSPs who get staffing right don’t have better intuition. They have better information.“The MSPs who get staffing right don’t have better intuition than you do. They just stopped making $60,000 decisions based on who quit last week.”
A Different Question to Ask Yourself
The next time someone on your team is struggling, before you open a job board, ask a different question: do I actually know what our productive hours or utilization looks like across my team right now? Not an estimate. Not a feeling based on who’s been grumpy in standup. Actual numbers. If the answer is no, that’s where the problem lives. Not in the recruiting pipeline. Not in the job market. Not in compensation benchmarks. It lives in the gap between what’s happening on your team and what you can see. Fix the visibility. Then fix the hire.


